Rethinking GraphQL Query Design in SitecoreAI: Avoiding Complexity Limits
Published: 27 February 2026

Introduction
When working with SitecoreAI and Experience Edge, GraphQL becomes the backbone of content delivery. It offers flexibility, precise field selection, and efficient data retrieval. However, that flexibility can sometimes lead to unexpected architectural challenges—especially when query complexity limits come into play.
In one of our implementations, we encountered a scenario that seemed straightforward at first: resolve a category from a datasource item and then fetch related items based on that category.
While simple in theory, the implementation introduced hidden architectural challenges.
This article walks through the real-world problem, why it occurred, and the architectural adjustment that resolved it effectively.
The Scenario
We had a component that received a datasource item. That datasource contained a Lookup field named Category Type. Based on the selected category, we needed to:
- Fetch related content items
- Limit the result set to the first five items
- Retrieve only essential fields such as name and path
- Ensure performance and production safety
The Problem Statement
When combining lookup resolution and search into one nested GraphQL query, we started encountering:
“Query complexity limit exceeded”
This is common in SitecoreAI. Experience Edge enforces query complexity limits to prevent overly expensive operations and protect performance across environments.
Even though we were fetching only five items, the internal cost of:
- Lookup traversal
- Search filters
- Nested field resolution
- Multiple field selections
Accumulated rapidly and exceeded the permitted complexity threshold.
GraphQL complexity isn’t just about how many items you fetch. It is influenced by how deeply and broadly the content graph is traversed.
The more responsibilities you give a single query, the more expensive it becomes.
Understanding: Why This Issue Occurred
GraphQL assigns a complexity score based on several factors:
- Depth of nested fields
- Use of search operations
- Number of filters
- Field resolution cost
- Result size
In our case, the query attempted to:
- Resolve a datasource item
- Traverse a Lookup field
- Extract a target item ID
- Execute a search query
- Fetch multiple fields from results
While this worked initially, scaling it even slightly pushed the complexity score beyond allowed limits. The issue wasn’t incorrect syntax.
It was architectural design.
The Step-by-Step Solution
Instead of trying to optimize a single heavy query, we split responsibilities into two focused queries.
Step 1: Resolve the Category Type
The first query retrieves only the category ID from the datasource.
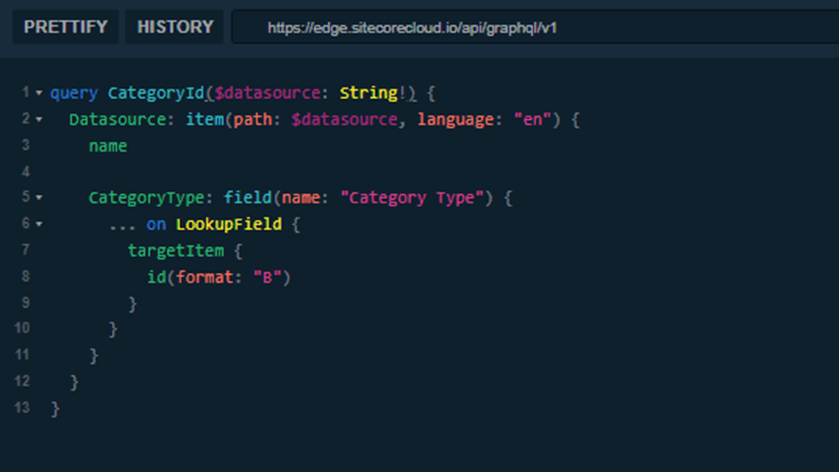
This query is lightweight.
It does exactly one thing: resolve the category identifier.
There is no search logic here.
No nested result fetching.
No unnecessary field traversal.
Step 2: Execute the Search Using the Category ID
Once the category ID is resolved, we execute a separate search query.
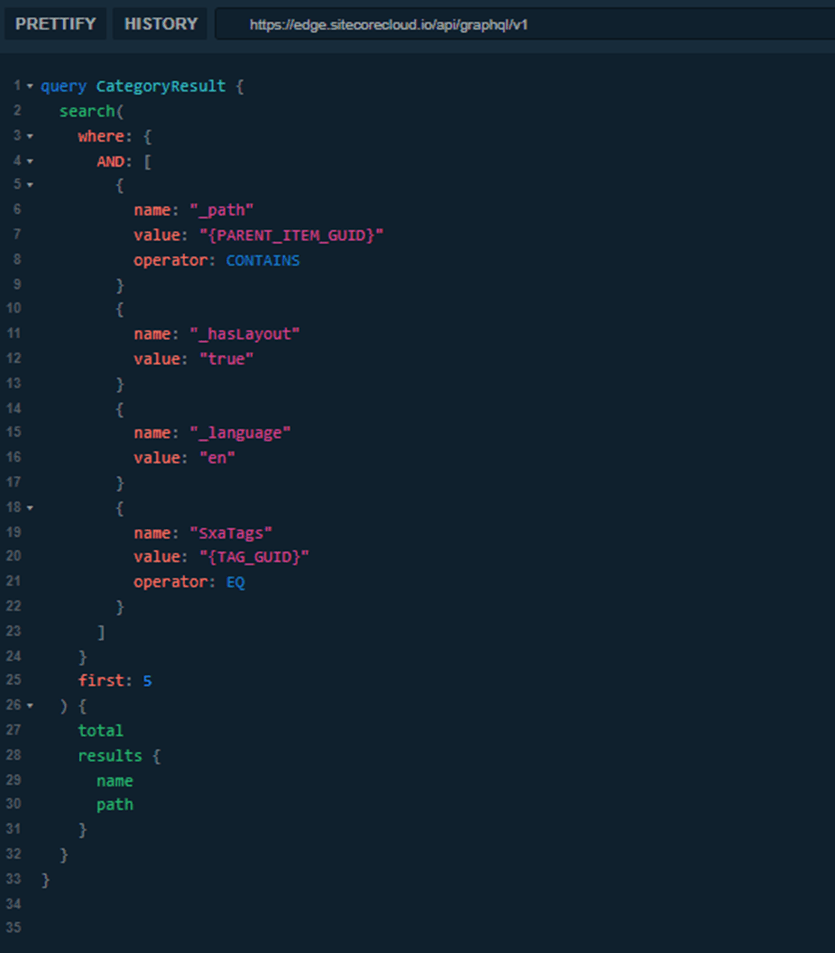
This query is also focused.
It performs a search operation and returns only what is required.
By separating concerns, each query remains within acceptable complexity limits.
How the Data Flows: From Lookup to Rendered Results
To understand why splitting the queries works, it helps to look at the actual flow.
First, the component runs the “CategoryId” query against the datasource item. This query does only one thing: it resolves the “Category Type” lookup field and extracts the target item ID. At this stage, no search is executed. We are simply retrieving a single identifier.
Once the Category ID is available, the frontend passes that ID into the second query. This search query uses the resolved ID as a filter (for example, within the “_path” condition) to retrieve the first five matching items.
So, the flow becomes:
Datasource → Resolve Category ID → Pass ID to Search Query → Fetch Results → Render on Page
By separating these responsibilities, we avoid combining lookup resolution and search execution into one heavy GraphQL operation.
Frontend Implementation Pattern
On the frontend, we structured the component so that it dynamically generates the search query after resolving the category ID.

This pattern ensures:
• Each operation has a single responsibility
• Complexity is distributed rather than compounded
Why This Solution Works Best
There are several architectural advantages to this approach.
1. Reduced Query Complexity
Each query performs one logical responsibility. This keeps complexity scores lower and avoids hard limits.
2. Better Maintainability
When lookup logic changes, only the first query needs modification.
When search logic evolves, only the second query changes.
They are decoupled.
3. Scalable Architecture
As requirements grow - more filters, more fields, additional categories, you can scale horizontally rather than increasing query depth.
Conclusion
In SitecoreAI projects, it is tempting to consolidate logic into a single powerful GraphQL query. While this may seem efficient initially, it can introduce hidden performance costs and complexity risks.
By separating lookup resolution and search execution into distinct queries, we achieved:
• Lower complexity scores
• Cleaner frontend architecture
• Better scalability
The solution was not about writing smarter GraphQL.
It was about designing smarter data flow.
Sometimes the best optimization is architectural clarity.

Keyur Nayi- Technical lead - ADDACT
Technical lead - ADDACT
Keyur is a Technical Lead at Addact with 9+ years of experience in enterprise CMS and software engineering. He is certified in Sitecore XM Cloud, OrderCloud, Sitecore 10 .NET, and SitecoreAI CMS for Developers (2025), specializing in scalable, cloud-ready and AI-driven implementations.
His technical stack includes ASP.NET/Core, C#, MVC, jQuery, and Azure/AWS, enabling high-performance, cross-platform digital solutions.